Comparison of AI tools for academic research
In the current age of AI boom, we are all tempted to use available AI tools for carrying out academic research. But how effective are these tools in helping us with our work? Every tool has different strengths and limitations and are suited for specific purposes. It is important to know the capabilities of each AI tool to make the best use of these for academic research.
To understand the quality of the results given and the level of adherence to instructions of various AI tools, I developed a single prompt and used it on five different AI platforms.
Prompt: Give me at least 5 high-quality recent references from peer-reviewed journals on HER2-negative metastatic gastric cancer. Avoid review articles.
I then analyzed the quality of the results and whether the AI tool had adhered to the instruction on avoiding review articles, displaying recent articles, and displaying results only from peer-reviewed journals.
Here is a summary of my analysis.
ChatGPT

This tool gave me 6 high-quality references reporting the results of clinical trials of various therapies for advanced HER2-negative gastric cancer. Two of the articles were three-year follow-ups of clinical trials that had already been provided as references, so, essentially, there were only 4 unique studies. None of them were review articles and all of them were in the year range of 2021-2024. It also provided a one-line summary of each article and offered to export the references into a BibTeX or Endnote bibliography.
Perplexity

This tool gave me 5 high-quality references on HER2-negative metastatic gastric cancer. However, I found that not all of them might be relevant to academic research. For instance, one of them was an analysis of development of HER2-low expression and HER2-positive tumours from HER2-negative tumours. Another was a comparison of clinicopathological features and clinical outcomes between these three tumour types. Yet another article was an analysis of the suitability of eligibility criteria of the CheckMate 649 trial for HER2-negative gastric cancer – a reference to the results of this trial would have been more relevant. Only two articles were studies on actual findings of potential therapies for HER2-negative metastatic gastric cancer. All references were between 2024-2025 and none of them were review articles.
Gemini

This tool gave me 5 high-quality references of clinical trials for advanced HER2-negative gastric cancer. The references provided findings of different clinical trials and none of them were follow-up studies. It also provided the study type and a short summary of each article. The articles were in the year range of 2023-2025 and none of them were review articles.
Grok

This tool gave me 5 high-quality references on various topics such as first-line therapy, maintenance therapy, third-line therapy, a retrospective cohort study on the efficacy of a therapy administered previously, and the prognostic efficacy of a blood marker for advanced HER2-negative gastric cancer. Thus, each of them provided a unique perspective on the topic. However, it did not provide any summary of the articles. The references were in the year range of 2021-2024 and none of them were review articles.
Claude

This tool provided only 3 high-quality references. One result was just the names of two clinical trials and a reference to a non-peer-reviewed article in a medical publication, while another was a review article. Of the three references provided, two reported findings of the same clinical trial while one was a study on the evolution of HER2 status in gastric cancer. They were in the year range of 2023-2025.
Comparative analysis
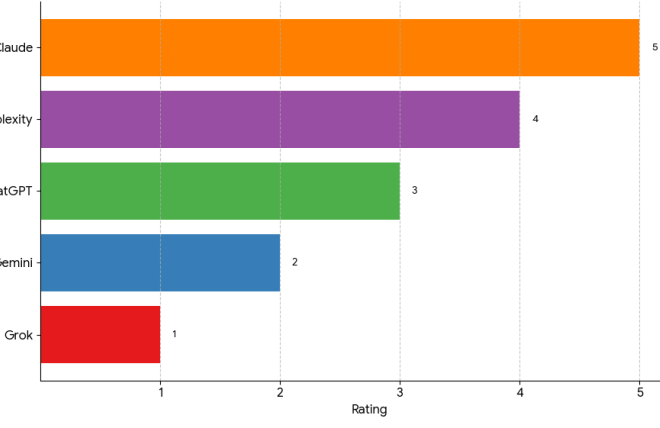
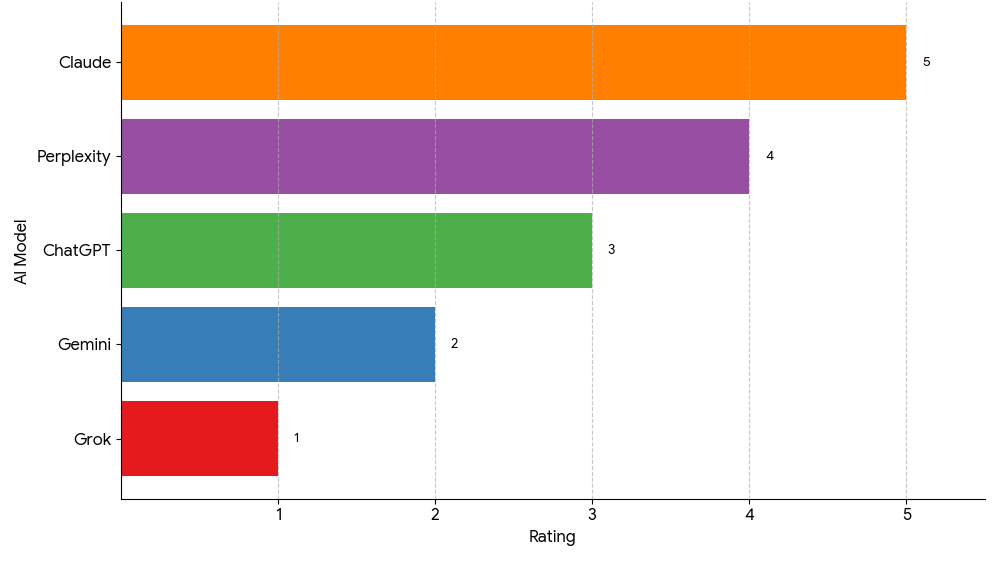
Based on the results of my prompt, I would rate Grok as 1, Gemini as 2, ChatGPT as 3, Perplexity as 4, and Claude as 5.
Grok followed every instruction to the letter and went above and beyond by providing references with unique perspectives. It understood what a student might require for academic research on a particular topic and fulfilled those expectations. Second would be Gemini because while it also provided relevant references, they were all clinical trials. This would also be very useful for a student looking for some high-quality articles to start their literature search.
I rated ChatGPT as third because it provided four unique articles on the topic with two being follow-up studies. When writing a literature review, you would ideally want to use only the most recent reference of a particular clinical trial as that would contain the most updated results. Fourth was perplexity which, although followed instructions, gave several articles that were irrelevant for a targeted literature review. I might have given Perplexity a pass thinking that it still followed the instructions of the prompt; however, the other tools did a better job at following the same prompt. Finally, I feel Claude shouldn’t even be in the list considering that it completely ignored the instructions and gave only one usable reference.
It should be noted that I did not specify the definition of “recent articles” in the prompt, i.e. I did not provide a specific year range. This could be one of the reasons that Perplexity provided several irrelevant references because it narrowed down the prompt to as little as 1 to 2 years. By increasing the year range to 3 years, Gemini was able to provide more relevant references and further increasing the year range led Grok to provide extremely relevant references.
Thus, for conducting academic research or to get some high-quality articles on a very specific topic, Grok would be the most ideal candidate.